Log4Shell Learnings
There are many things that I learned from the Log4j2 vulnerability (CVE-2021-44228)
In this post I’ll describe some of them and at the end I’ll show how to use a very basic logger based on Logback.
- Much more than a logger
- Vulnerabilities can live for a lonnngg time
- Maven settings
- Gradle settings
- Hotpatch
- Creating a simple logger
1. Much more than a logger
I think it was shocking for many people to find out that that functionality even existed.
It also has an extensive documentation, which most of the times is a good thing, but it might also be a sign that it does much more than a logger should do.
For example, here’s the lookups page
2. Vulnerabilities can live for a lonnngg time
LOG4J2-313 feature request was accepted, implemented, and merged in 2013
https://twitter.com/brunoborges/status/1473813280384643072?s=20
3. Maven Settings
Changing Dependencies’ version
Many dependencies use a property to specify the version, and these properties can be overriden, eg:
<logback.version>1.2.8</logback.version>
<log4j2.version>2.17.1</log4j2.version>
Of course this should be done with caution, because you might be breaking your dependencies.
You can also explicit declare the dependency in your pom.xml, eg:
<!-- https://mvnrepository.com/artifact/org.apache.logging.log4j/log4j-core -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.17.1</version>
</dependency>
Maven Enforcer Plugin
If you have a #Maven parent POM for your org or project, here’s an enforcer rule to put into it which will ban any current of future usage of vulnerable #log4j2 versions.
https://gist.github.com/gunnarmorling/8026d004776313ebfc65674202134e6d
https://twitter.com/gunnarmorling/status/1469603432269062146

4. Gradle Settings
Cédric Champeau
@CedricChampeau
If you are using #Gradle, not using log4j directly but want to make sure you are not bringing a vulnerable log4j dependency transitively, you can enforce usage of a patched version like this. #Log4Shell
https://twitter.com/CedricChampeau/status/1469608906196410368

5. Hotpatch
This is a great way to attack the log4j problem: being able to hotpatch a running system is a pretty unique capability
Log4jHotPatch
This is a tool which injects a Java agent into a running JVM process. The agent will attempt to patch the lookup() method of all loaded org.apache.logging.log4j.core.lookup.JndiLookup instances to unconditionally return the string “Patched JndiLookup::lookup()”. It is designed to address the CVE-2021-44228 remote code execution vulnerability in Log4j without restarting the Java process. This tool will also address CVE-2021-45046.
https://github.com/corretto/hotpatch-for-apache-log4j2
More info on how Java agent works:
- The definitive guide to Java agents by Rafael Winterhalter
- https://stackoverflow.com/questions/27851588/what-is-premain-and-how-does-it-get-called
- https://docs.oracle.com/javase/8/docs/api/java/lang/instrument/package-summary.html
6. Creating a Simple Logger
Let’s create a logger that have the following APIs:
- LOG.log_level(msg)
- LOG.getLevel()
Where log_level can be: trace, debug, info, warn and error.
Logback also has
OFF and ALL.
Logback’s Architecture explains really well why you should use parameterized logging, but I’ll not implement it for now.
Logback has lot’s of different ways to configure the logger.
This one will be really simple, with just one appender FileAppender and
it will work asyncronously using AsyncAppenderBase.
I tried to extract the minimum possible classes from Logback and it end up with the following classes:
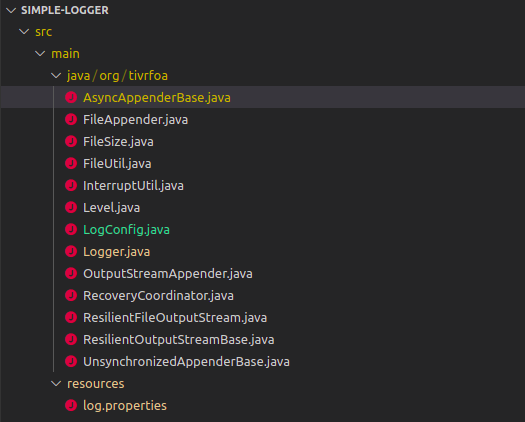
The 2 only configurations that the user can do is the general log level
and the output file. These can be set in log.properties, eg:
output-file=test-async2.txt
level=TRACE
We have a problem in a multi-threaded system, where many threads
are trying to write to the file.
I liked this answer from StackOverflow:
Have a single file writer thread which keeps reading from blocking queue and writing to a file. All other 20 threads will just put the data in blocking queue. This will prevent contention between 20 writer threads.
And this seems to be the way it’s implemented in Logback:
...
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
/**
* This appender and derived classes, log events asynchronously. In order to
* avoid loss of logging events, this appender should be closed. It is the
* user's responsibility to close appenders, typically at the end of the
* application lifecycle.
* <p>
* This appender buffers events in a {@link BlockingQueue}. {@link Worker}
* thread created by this appender takes events from the head of the queue, and
* dispatches them to the single appender attached to this appender.
* <p>
* Please refer to the
* <a href="http://logback.qos.ch/manual/appenders.html#AsyncAppender">logback
* manual</a> for further information about this appender.
* </p>
I’ll also only use explicit/concret classes … No service providers, interfaces, …
Services offer flexibility, but I don’t like all the work that needs to be done to load them:
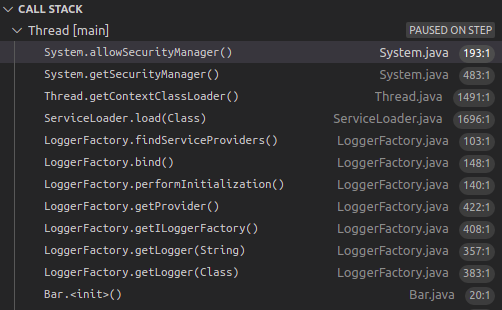
I also like to immeditialy see what’s being used, instead of having to
look at dependency:tree and jar/war files.
The repository for this simple logger is here: https://github.com/tivrfoa/java-simple-async-logger
Of course, you should definitely not use it in production.
Use Logback instead.
Appendix
Logback prints and debugging
Some random stuff about Logback while I was studying its source code.
LogbackServiceProvider#initialize
@Override
public void initialize() {
defaultLoggerContext = new LoggerContext();
defaultLoggerContext.setName(CoreConstants.DEFAULT_CONTEXT_NAME);
initializeLoggerContext();
defaultLoggerContext.start();
markerFactory = new BasicMarkerFactory();
mdcAdapter = new LogbackMDCAdapter();
}
LoggerContext
Writing Ouptut
FileAppender -> OutputStreamAppender
public class FileAppender<E> extends OutputStreamAppender<E> {
public class OutputStreamAppender<E> extends UnsynchronizedAppenderBase<E> {
abstract public class UnsynchronizedAppenderBase<E> extends ContextAwareBase implements Appender<E> {
private void writeBytes(byte[] byteArray) throws IOException {
if(byteArray == null || byteArray.length == 0)
return;
lock.lock();
try {
this.outputStream.write(byteArray);
if (immediateFlush) {
this.outputStream.flush();
}
} finally {
lock.unlock();
}
}
/**
* <p>
* Sets the @link OutputStream} where the log output will go. The specified
* <code>OutputStream</code> must be opened by the user and be writable. The
* <code>OutputStream</code> will be closed when the appender instance is
* closed.
*
* @param outputStream
* An already opened OutputStream.
*/
public void setOutputStream(OutputStream outputStream) {
lock.lock();
try {
// close any previously opened output stream
closeOutputStream();
this.outputStream = outputStream;
if (encoder == null) {
addWarn("Encoder has not been set. Cannot invoke its init method.");
return;
}
encoderInit();
} finally {
lock.unlock();
}
}
logback-core/src/main/java/ch/qos/logback/core/AsyncAppenderBase.java
private void put(E eventObject) {
if (neverBlock) {
blockingQueue.offer(eventObject);
} else {
putUninterruptibly(eventObject);
}
}
private void putUninterruptibly(E eventObject) {
boolean interrupted = false;
try {
while (true) {
try {
blockingQueue.put(eventObject);
break;
} catch (InterruptedException e) {
interrupted = true;
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}
java.util.concurrent.ArrayBlockingQueue
/**
* Inserts the specified element at the tail of this queue, waiting
* for space to become available if the queue is full.
*
* @throws InterruptedException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public void put(E e) throws InterruptedException {
Objects.requireNonNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
logback-classic/src/main/java/ch/qos/logback/classic/PatternLayout.java
protected String writeLoopOnConverters(E event) {
StringBuilder strBuilder = new StringBuilder(INTIAL_STRING_BUILDER_SIZE);
Converter<E> c = head;
while (c != null) {
c.write(strBuilder, event);
c = c.getNext();
}
return strBuilder.toString();
}
Async has its own thread:
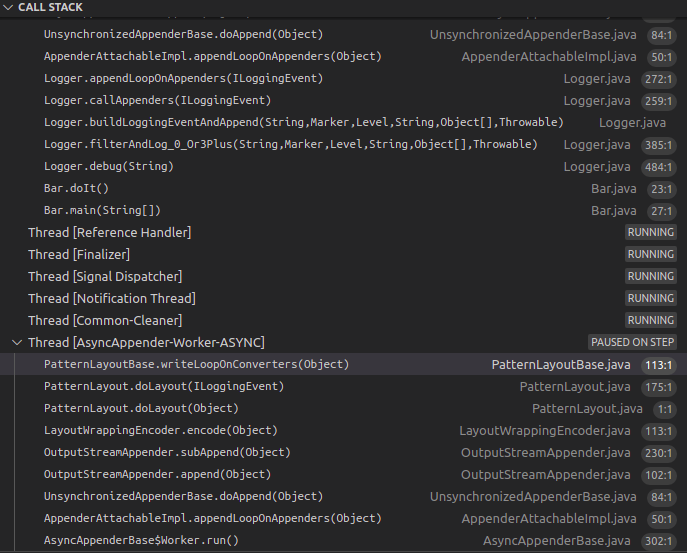
logback/logback-core/src/main/java/ch/qos/logback/core/AsyncAppenderBase.java
class Worker extends Thread {
public void run() {
AsyncAppenderBase<E> parent = AsyncAppenderBase.this;
AppenderAttachableImpl<E> aai = parent.aai;
// loop while the parent is started
while (parent.isStarted()) {
try {
List<E> elements = new ArrayList<E>();
E e0 = parent.blockingQueue.take();
elements.add(e0);
parent.blockingQueue.drainTo(elements);
for (E e : elements) {
aai.appendLoopOnAppenders(e);
}
} catch (InterruptedException e1) {
// exit if interrupted
break;
}
}
addInfo("Worker thread will flush remaining events before exiting. ");
for (E e : parent.blockingQueue) {
aai.appendLoopOnAppenders(e);
parent.blockingQueue.remove(e);
}
aai.detachAndStopAllAppenders();
}
}
logback-core/src/main/java/ch/qos/logback/core/spi/AppenderAttachableImpl.java
/**
* Call the <code>doAppend</code> method on all attached appenders.
*/
public int appendLoopOnAppenders(E e) {
int size = 0;
final Appender<E>[] appenderArray = appenderList.asTypedArray();
final int len = appenderArray.length;
for (int i = 0; i < len; i++) {
appenderArray[i].doAppend(e);
size++;
}
return size;
}
parent.blockingQueue.take(); seems to be the key for how all of
this works:
/*
E java.util.concurrent.BlockingQueue.take() throws InterruptedException
Retrieves and removes the head of this queue, waiting if necessary until an element becomes available.
Returns:
the head of this queue
Throws:
InterruptedException - if interrupted while waiting
*/
Great answer about queueSize, includeCallerData and neverBlock here:
queueSize: the bigger this is the less blocking there will be on the application threads. If the async appender’s queue fills up, then application threads will be blocked from logging new events until the worker thread has had a chance to remove items from the queue. So, increasing the queueSize will improve throughput if the application tends to produce enough near concurrent log events to fill up the queue. But bear in mind that this gain in throughput is only relevant if the application is capable of swamping the existing queue size and it comes at the cost of heap usage.
includeCallerData: reading caller supplied data from log events can be expensive, you’ll typically find that setting this to false improves performance and unless you have some bespoke caller supplied data in your log events you won’t actually lose any data
neverBlock: setting this to true will prevent any blocking on your application threads but it comes at the cost of lost log events if the async appender’s internal buffer fills up.
Logback properties: https://logback.qos.ch/manual/appenders.html
queueSize:The maximum capacity of the blocking queue. By default, queueSize is set to 256.
immediateFlush: The default value for immediateFlush is ‘true’. Immediate flushing of the output stream ensures that logging events are immediately written out and will not be lost in case your application exits without properly closing appenders. On the other hand, setting this property to ‘false’ is likely to quadruple (your mileage may vary) logging throughput. Again, if immediateFlush is set to ‘false’ and if appenders are not closed properly when your application exits, then logging events not yet written to disk may be lost.
maxFlushTime: Depending on the queue depth and latency to the referenced appender, the AsyncAppender may take an unacceptable amount of time to fully flush the queue. When the LoggerContext is stopped, the AsyncAppender stop method waits up to this timeout for the worker thread to complete. Use maxFlushTime to specify a maximum queue flush timeout in milliseconds. Events that cannot be processed within this window are discarded. Semantics of this value are identical to that of Thread.join(long).
AsyncAppender will wait for the worker thread to flush up to the timeout specified in maxFlushTime. If you find that queued events are being discarded during close of the LoggerContext, you may need to increase the time out. Specifying a value of 0 for maxFlushTime will force the AsyncAppender to wait for all queued events to be flushed before returning from the stop method.
discardingThreshold: By default, when the blocking queue has 20% capacity remaining, it will drop events of level TRACE, DEBUG and INFO, keeping only events of level WARN and ERROR. To keep all events, set discardingThreshold to 0.
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
logback-classic/src/main/java/ch/qos/logback/classic/spi/LoggingEvent.java
/**
* This method should be called prior to serializing an event. It should also
* be called when using asynchronous or deferred logging.
* <p/>
* <p/>
* Note that due to performance concerns, this method does NOT extract caller
* data. It is the responsibility of the caller to extract caller information.
*/
public void prepareForDeferredProcessing() {
this.getFormattedMessage();
this.getThreadName();
// fixes http://jira.qos.ch/browse/LBCLASSIC-104
this.getMDCPropertyMap();
}
OutputStreamAppender#subAppend -> LayoutWrapperEncoder#encode
public byte[] encode(E event) {
String txt = layout.doLayout(event);
return convertToBytes(txt);
}
Logback example configuration file for Async Appender
<configuration debug="true">
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>/some/path/async.log</file>
<bufferSize>256KB</bufferSize>
<immediateFlush>true</immediateFlush>
<append>true</append>
<encoder>
<pattern>%d %p [%t] %logger - %m%n</pattern>
</encoder>
</appender>
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<queueSize>500</queueSize>
<maxFlushTime>1000</maxFlushTime>
<appender-ref ref="FILE" />
</appender>
<logger name="chapters.architecture" level="TRACE" />
<root level="TRACE">
<appender-ref ref="ASYNC" />
</root>
</configuration>
Java native Thread
/src/java.base/share/native/libjava/Thread.c
static JNINativeMethod methods[] = {
{"start0", "()V", (void *)&JVM_StartThread},
JVM_ENTRY(void, JVM_StartThread(JNIEnv* env, jobject jthread))
JavaThread *native_thread = NULL;
// ...
NOT_LP64(if (size > SIZE_MAX) size = SIZE_MAX;)
size_t sz = size > 0 ? (size_t) size : 0;
native_thread = new JavaThread(&thread_entry, sz);
// Class hierarchy
// - Thread
// - JavaThread
// - various subclasses eg CompilerThread, ServiceThread
// - NonJavaThread
// - NamedThread
// - VMThread
// - ConcurrentGCThread
// - WorkerThread
// - WatcherThread
// - JfrThreadSampler
// - LogAsyncWriter
Distinguishing Interleaved Log Output from different Sources
This is an important feature …, but I’m not sure I want the simple logger to have it.
/**
* A <em>Mapped Diagnostic Context</em>, or MDC in short, is an instrument for
* distinguishing interleaved log output from different sources. Log output is
* typically interleaved when a server handles multiple clients
* near-simultaneously.
* <p/>
* <b><em>The MDC is managed on a per thread basis</em></b>. Note that a child thread
* <b>does not</b> inherit the mapped diagnostic context of its parent.
* <p/>
* <p/>
* For more information about MDC, please refer to the online manual at
* http://logback.qos.ch/manual/mdc.html
*
* @author Ceki Gülcü
*/
public class LogbackMDCAdapter implements MDCAdapter {
References
Important Logback classes: