Timeline of most important databases by Grok 3
1963
Integrated Data Store (IDS)
Developed by Charles Bachman at General Electric, IDS introduced the network data model, one of the earliest database systems.
1968
IBM Information Management System (IMS)
Released by IBM, IMS used a hierarchical model, organizing data in tree-like structures.
1970
Edgar F. Codd’s Relational Model
Edgar Codd published a groundbreaking paper introducing the relational database model, laying the foundation for modern databases.
1973
VSAM (Virtual Storage Access Method)
Introduced by IBM for mainframe systems, VSAM was a file access method that enhanced data retrieval and storage efficiency for large datasets.
1974
IBM System R
IBM’s System R was one of the first relational database management systems (RDBMS), introducing SQL (Structured Query Language) to query relational data.
1976
Adabas
Developed by Software AG, Adabas was a high-performance inverted list database optimized for large-scale transaction processing.
1979
Oracle Database
Released by Oracle Corporation, this was the first commercial RDBMS based on Codd’s relational model.
1983
IBM DB2
Built on System R, DB2 became a leading RDBMS for mainframes, widely adopted for robust transaction support.
1986
SQL ANSI Standard
The American National Standards Institute (ANSI) standardized SQL, establishing it as the universal language for relational databases.
1995
MySQL and PostgreSQL
These open-source RDBMS systems emerged: MySQL for its speed and simplicity, and PostgreSQL for its robustness and SQL standards compliance.
2009
Redis
An in-memory data structure store, Redis functions as a database, cache, or message broker, known for its speed and versatility.
2012
Google Spanner
A globally distributed RDBMS, Spanner combined relational consistency with NoSQL scalability, introducing synchronized global clocks for distributed transactions.
Prompting ChatGPT: most revolutionary databases
Here’s a concise, chronological overview of some of the most revolutionary database systems and models, showing how each shifted the paradigm of data management:
The Navigational Era (1960s)
- Integrated Data Store (IDS) – 1961: Charles Bachman’s IDS is generally considered the first “proper” database management system, introducing the idea of a navigational interface for data retrieval.
- IBM Information Management System (IMS) – 1967: Built for NASA’s Apollo program, IMS was the first widely used hierarchical database, proving the value of structured, computer‑based data storage.
The Relational Era (1970s–1980s)
- Relational Model – 1970: E.F. Codd’s seminal paper “A Relational Model of Data for Large Shared Data Banks” laid the mathematical foundation for organizing data into tables and set-based querying.
- IBM System R – 1974: The first implementation of Codd’s model, introducing SQL and demonstrating that relational systems could be practical.
- INGRES – 1974: Developed at UC Berkeley, INGRES used the QUEL query language and influenced many later systems (including PostgreSQL).
- Oracle v2 – 1979: The first commercial relational DBMS, Oracle Version 2 brought SQL to the market and kick‑started the RDBMS industry.
The Object‑Relational & Open‑Source Era (1986–present)
- PostgreSQL (Postgres) – 1986: Evolved from INGRES, Postgres introduced true extensibility and object‑relational features (user‑defined types, functions, rules), blending the power of relational models with object concepts.
The Document & Key‑Value Era (1989–1990s)
- Lotus Notes – 1989: One of the first document‑centric, application‑building platforms, Lotus Notes treated data as self‑contained documents and foreshadowed NoSQL approaches.
- Berkeley DB – 1991: An embeddable key‑value store for local applications, Berkeley DB showed how lightweight, non‑relational storage could power everything from desktop apps to servers.
The Web‑Scale NoSQL Era (2005–2010s)
- Apache CouchDB – 2005: A JSON/HTTP‑based document store that emphasized ease of use, master‑master replication, and eventual consistency for web‑scale apps.
- Google Bigtable – 2006: A sparse, distributed, persistent multidimensional sorted map (column‑family store) built to power Google Search and many other services at massive scale.
- Amazon Dynamo – 2007: A highly available, partition‑tolerant key‑value store underpinning Amazon’s e‑commerce platform, pioneering eventual‑consistency techniques.
- MongoDB – 2009: Popularized JSON‑style documents with dynamic schemas and rich secondary indexes, enabling rapid development of modern, schema‑flexible applications.
The Distributed SQL Era (2012–present)
- Google Spanner – 2012: The first system to offer globally‑distributed, synchronously‑replicated ACID transactions across datacenters, using a novel TrueTime API for external consistency.
Each of these systems not only introduced new data models or architectures but also reshaped expectations around scalability, consistency, and ease of development—setting the stage for the next wave of innovation in data management.
Prompt: Weren’t any important inventions/ideas in the database field after 2012?
Great question—and yes, plenty of revolutionary ideas and systems emerged post-2012, building on past breakthroughs while adapting to modern demands like global scale, real-time analytics, hybrid workloads, and cloud-native architectures. Here’s a rundown of some key post-2012 innovations:
🪨 1. CockroachDB (2015) – Distributed SQL
- Inspired by Google Spanner, but open-source and designed for broad enterprise adoption.
- Fully distributed PostgreSQL-compatible SQL engine with ACID transactions and geo-partitioning.
- Self-healing, auto-rebalancing nodes—a massive step for resilient, global apps.
☁️ 2. Snowflake (2014, major rise after 2016) – Cloud-Native Data Warehousing
- Completely decouples storage and compute, allowing dynamic scaling and pay-per-use.
- Multi-cluster shared data architecture made data warehousing as a service truly elastic.
- Query time data sharing and seamless multi-tenant environments revolutionized collaboration.
📊 3. Apache Arrow (2016) – In-Memory Columnar Data Format
- A high-performance standard for zero-copy data exchange between systems like Pandas, Spark, and databases.
- Led to major boosts in analytics, ML pipelines, and cross-system interoperability.
⏱️ 4. Materialize (founded 2019) – Streaming SQL
- Brings real-time views and incremental computation to SQL queries over streaming data.
- Think “PostgreSQL meets Kafka”—great for event-driven systems that want up-to-date answers, not just stale batch results.
🔁 5. Delta Lake, Apache Iceberg, Hudi (2018–2020) – Transactional Data Lakes
- Enable ACID transactions on data lakes, solving the messiness of raw cloud storage (like S3) for analytics.
- Key to the rise of the “lakehouse” architecture: one system for both BI and ML workloads.
🧠 6. Vector Databases (Pinecone, Weaviate, Qdrant, Milvus) – 2020+
- Specialized for storing and searching high-dimensional vector embeddings (used in AI, NLP, recommender systems).
- Power the backend of semantic search, chatbots, and LLM-enhanced apps.
⚡ 7. HTAP / Multi-Modal DBs – Real-Time Hybrid Workloads
- Databases like SingleStore, TiDB, and ClickHouse allow OLTP + OLAP on the same engine.
- Blur the line between operational and analytical processing—faster insights with fewer systems.
These post-2012 innovations are all about scale, flexibility, and developer experience. The field didn’t slow down—it just shifted from foundational theory to engineering reality at web scale.
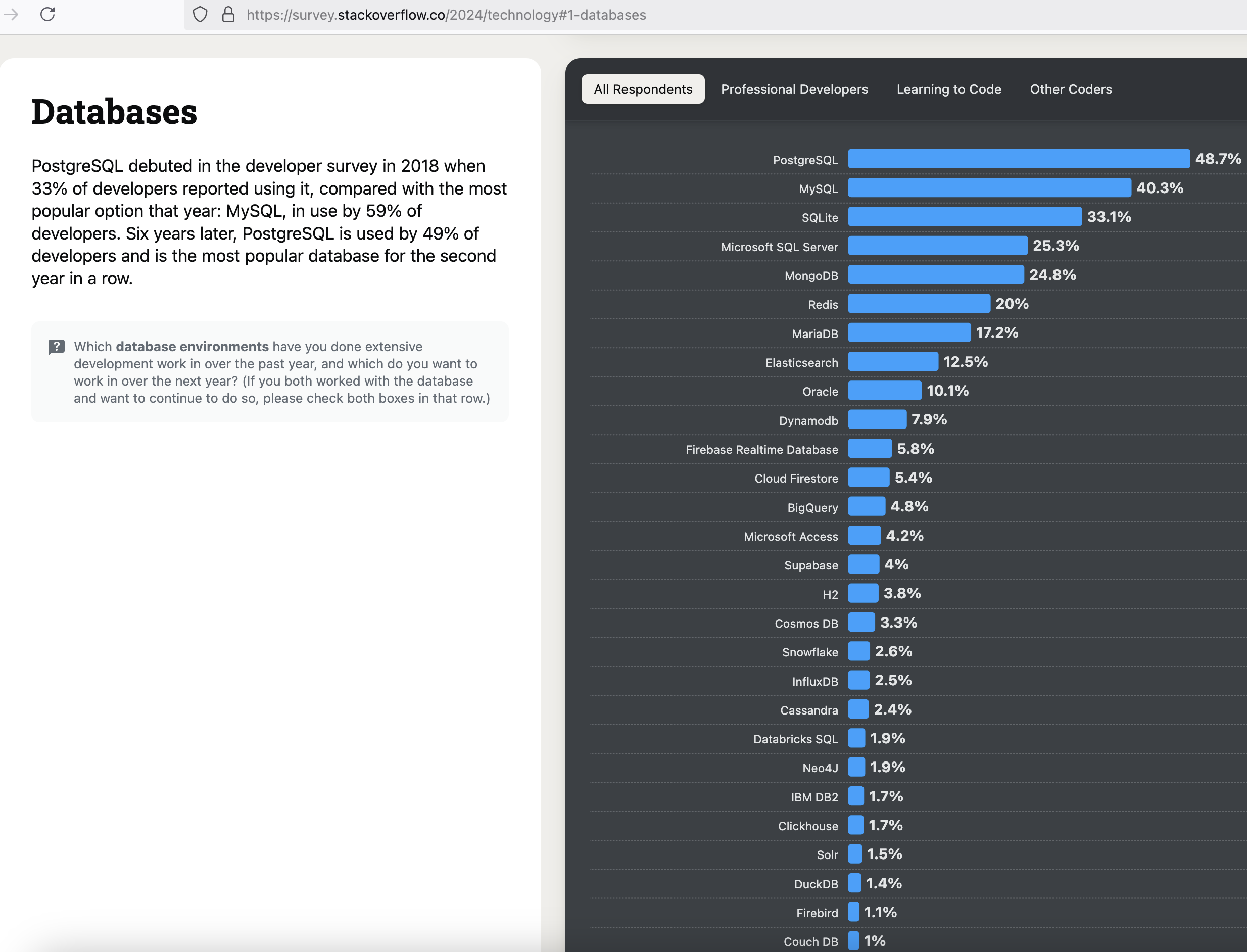
2024 StackOverflow Survey - Most Popular Databases
PostgreSQL debuted in the developer survey in 2018 when 33% of developers reported using it, compared with the most popular option that year: MySQL, in use by 59% of developers. Six years later, PostgreSQL is used by 49% of developers and is the most popular database for the second year in a row.